7ビット符号
JIS
区番号を1バイト目、点番号を2バイト目にした、16ビットの符号とするのですが、 区点番号に16進の 20 を加えておくGL領域用符号と、 16進の A0 を加えておく GR領域用符号の2種類があります。以下に例を掲げます。 区点番号を16進表示することは一般的でないのですが、JIS符号との関連を示すために掲げています。
| 区 | 点 | 字形 | コード(16進) | |||
|---|---|---|---|---|---|---|
| (10進) | (16進) | (10進) | (16進) | GL | GR | |
| 03 | 03 | 19 | 13 | 3 | 2333 | A3B3 |
| 03 | 03 | 65 | 41 | a | 2361 | A3E1 |
| 04 | 04 | 01 | 01 | ぁ | 2421 | A4A1 |
| 04 | 04 | 02 | 02 | あ | 2422 | A4A2 |
| 16 | 10 | 01 | 01 | 亜 | 3021 | B0A1 |
| 16 | 10 | 02 | 02 | 唖 | 3022 | B0A2 |
| 16 | 10 | 03 | 03 | 娃 | 3023 | B0A3 |
| 16 | 10 | 04 | 04 | 阿 | 3024 | B0A4 |
| 16 | 10 | 05 | 05 | 哀 | 3025 | B0A5 |
| 23 | 17 | 24 | 36 | 慶 | 3744 | B7C4 |
| 56 | 38 | 70 | 46 | 應 | 5866 | D8E6 |
| 17 | 11 | 94 | 5E | 応 | 317E | B1FE |
| 84 | 54 | 04 | 04 | 瑤 | 7424 | F4A4 |
Shift−JIS
1バイト目 81〜9F ... 31 ヶ所
E0〜EF ... 16 ヶ所 計 47
2バイト目 40〜7E ... 63 ヶ所
80〜FC ... 125 ヶ所 計 188 ―― 47 × 188 = 8836 = 94 × 94
- 区 が 1〜61 で奇数の場合、区 に 257を加えて 2で割った値を 1バイト目にする。
点 が 1〜63 なら 63 を加えた値を、そうでなければ64を加えた値を 2バイト目にする。 - 区 が 2〜62 の偶数の場合、区 に 256を加えて、2で割った値を1バイト目にする。
点に 158 を加えた値を 2バイト目にする。 - 区 が 63〜93の奇数の場合、区 に 385 を加えて2で割った値を1バイト目にする。
点 が 1〜63であれば、63を加えた値、そうでなければ64を加えた値を2バイト目にする。 - 区 が 64〜94の偶数の場合、区 に 384 を加えて2で割った値を1バイト目にする。
点 に 158 を加えた値を 2バイト目にする。
| 区 | 点 | 字形 | コード(10進) | コード SJIS | |
|---|---|---|---|---|---|
| 1バイト目 | 2バイト目 | ||||
| 03 | 19 | 3 | 130 | 82 | 8252 |
| 03 | 65 | a | 130 | 129 | 8281 |
| 04 | 01 | ぁ | 48 | 65 | 3041 |
| 04 | 02 | あ | 48 | 66 | 3042 |
| 16 | 01 | 亜 | 136 | 159 | 889F |
| 16 | 02 | 唖 | 136 | 160 | 88A0 |
| 16 | 03 | 娃 | 136 | 161 | 88A1 |
| 16 | 04 | 阿 | 136 | 162 | 88A2 |
| 16 | 05 | 哀 | 136 | 163 | 88A3 |
| 23 | 24 | 慶 | 140 | 99 | 8C63 |
| 56 | 70 | 應 | 156 | 228 | 9CE4 |
| 17 | 94 | 応 | 137 | 158 | 899E |
| 84 | 04 | 瑤 | 234 | 162 | EAA2 |
ISO-2022-JP
ISO-2022-JP はこの枠組みの中で、以下のようなエスケープシーケンスを用いて(「指示」や「呼び出し」を行い)、 ASCII、X 0201 ローマ字、X 0208漢字 を7ビットで扱おうというものです。
| 文字種 | エスケープシーケンス(16進) | エスケープシーケンス(文字表現) |
|---|---|---|
| ASCII | 1B 28 42 | ESC ( B |
| JIS ローマ字 | 1B 28 4A | ESC ( J |
| JIS カナ | ― | ― |
| 旧JIS | 1B 24 40 | ESC $ @ |
| 新JIS | 1B 24 42 | ESC $ B |
以下の約束があります。
- 行のはじめは、ASCII で始まる。
ASCII で始まる行はエスケープシーケンスなしで始まります。 - 行末では ASCII に戻しておく。
- JIS漢字についてはGL領域を使う。
ファイルのダンプ例が、 平成14年度質問と回答 2 の最後にあります。
EUC-JP
| エンコーディング | 符号長 | 字種 例 | コード | |
|---|---|---|---|---|
| ASCII | そのまま | 1バイト | A | 41 |
| JIS基本漢字 | GR領域 | 2バイト | あ | A4 A2 |
| JISカナ | 8Eでシングルシフト | 2バイト | ア | 8E 41 |
| JIS補助漢字 | 8Fでシングルシフト | 3バイト | 鷗 | 8F EC BF |
UTF-16LE とUTF-16BE
UCS-2 あるいは 16ビットのユニコード をそのまま符号にしたものです。 16ビットをバイトの列として、外部媒体や通信回線に送り出す際に、 16ビットの上8ビットを先に送り出す(ビッグエンディアン)か、 下8ビットを先に送り出すか(リトルエンディアン) の2種類のエンコーディングがあります。 Windows では通常リトルエンディアン( UTF-16LE )が使われます。 UTF-16 とは異なり、テキストの先頭にエンディアンを区別する BOM が付きません。
UTF-16
以下の方法で2バイトまたは4バイトに符号化されます。
UCS-2( 群00 面00 )の部分は16ビットをそのまま符号にします。
群00 の 面01 から 面10(第16面)については、 サロゲートペアとよばれる2つの16ビットの組で1文字の符号とします。
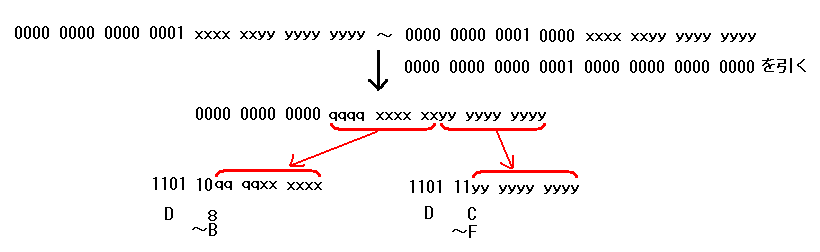
サロゲートペアに使うために、 UCS-2 の D800 〜 DFFF には文字が割り当てられていません。 このことにより、D8〜DB で始まる16ビットはサロゲートの上位、 DC〜DF で始まる16ビットはサロゲートの下位と判定され、逆変換が可能となります。
UCS-4の残りの部分(群00面11〜群7F面FF)については UTF-16 ではエンコードされません。
各々の16ビットをバイト列に変換する方法として、 16ビットの上8ビットを先に送り出す(ビッグエンディアン)か、 下8ビットを先に送り出すか(リトルエンディアン) の2種類のエンコーディングがあります。
ファイルの先頭、あるいは通信の最初にBOM とよばれる文字が付加されることがあります。 BOM によって、ビッグエンディアンかリトルエンディアンかを判定することができます。 BOM がない場合は、ビッグエンディアンと判定されます。
UTF-8
| コードポイント | 1バイト目 | 2バイト目 | 3バイト目 | 4バイト目 |
|---|---|---|---|---|
| 00000000 0xxxxxxx | 0xxxxxxx | |||
| 00000yyy yyxxxxxx | 110yyyyy | 10xxxxxx | ||
| zzzzyyyy yyxxxxxx | 1110zzzz | 10yyyyyy | 10xxxxxx | |
| 000uuuuu zzzzyyyy yyxxxxxx | 11110uuu | 10uuzzzz | 10yyyyyy | 10xxxxxx |
ひらがなが ¥u3040〜 、カタカナが ¥u30A0〜 、 CJK統合漢字が ¥u3400〜 ですから、漢字は3バイトになります。
¥uD800 〜 ¥uDFFF はサロゲートペアのためのコードポイントであり、エンコードの対象外です。 ¥u110000 以上の部分もエンコードの対象外です。
以上が、Unicode 4.0 の UTF-8 の定義です。 JIS X 0221-1 の「 付属書D(規定) UCS変換形式8 (UTF-8) 」 では、 5〜6バイト長の場合も定義されていて次のようになっています。
| オクテットの用途 | 形式(2進数) | 自由ビット数 | 最大UCS-4値 |
|---|---|---|---|
| 1オクテットの列の最初 | 0xxxxxxx | 7 | 0000 007F |
| 2オクテットの列の最初 | 110xxxxx | 5 | 0000 07FF |
| 3オクテットの列の最初 | 1110xxxx | 4 | 0000 FFFF |
| 4オクテットの列の最初 | 11110xxx | 3 | 001F FFFF |
| 5オクテットの列の最初 | 111110xx | 2 | 03FF FFFF |
| 6オクテットの列の最初 | 1111110x | 1 | 7FFF FFFF |
| 継続オクテット(2〜6番目) | 10xxxxxx | 6 |
修正UTF-8
- null すなわち ¥u0000 は、
2バイト形式にエンコードされます。
これにより、 文字列の中に 0016 というバイトが現れなくなります。 - 基本多言語面(BMP、¥u0000〜¥uFFFF)の文字を、1〜3バイト長のUTF−8で表現します。
- 16ビットを超える文字(¥u10000〜¥u10FFFF)はUTF−16のサロゲートペアで表現します。
この部分はJavaでは「補助文字」と呼ばれ、プログラム内では int で処理します。
UTF-32
エンディアンの問題だけが残ります。 たとえば、ABC で始まるバイト列を例にすると次のようになります。
| メモリ上の値 32ビットワード | エンコーディング | バイト列 |
|---|---|---|
|
00000041 00000042 00000043 |
UTF-32BE | 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32LE | 41 00 00 00 42 00 00 00 43 00 00 00 | |
| UTF-32 ビッグエンディアン | 00 00 FE FF 00 00 00 41 00 00 00 42 00 00 00 43 | |
| UTF-32 リトルエンディアン | FF FE 00 00 41 00 00 00 42 00 00 00 43 00 00 00 | |
| UTF-32 BOM なし | 00 00 00 41 00 00 00 42 00 00 00 43 |